Introduction
Doing business is about exchange — of goods and services, and of information support it all. This exchange is facilitated by documents entering the enterprise and going out to customers, suppliers and other stakeholders.
To optimize this exchange and achieve process improvement goals, businesses today need to ask these questions:
- How do we cost-effectively insert incoming documents into our business processes so that they get to the right places as efficiently as possible?
- How can we remove human intervention and manual paper handling from document processes?
- How can we improve the efficiency of our back-office operations and reduce human errors?
- What capabilities do we need?
As companies seek to reduce the use of paper, document capture is only part of the answer. The issue is much broader, raising the larger question of how to manage business processes that rely on information received in paper form as well as by fax or email. In answering that question, what matters most is what you want to do with the information.
No matter what channel a document comes through and what type of document it is, the challenge is how to remove manual handling inefficiency and risk of errors. When the information from incoming business documents has been captured, it needs to be analysed, understood and managed. This means putting the information through a workflow for validation and eventually routing this information to a business application and/or a storage repository. The more you can automate this process from end to end, the more value you can extract from inbound business documents.
Optical Character Recognition (OCR) technology has provided a functional means of making business documents machine-readable, OCR is most practical for structured documents, which have formats and layouts that do not vary.
But with OCR, human intervention may still be required to assure the quality of the captured data. Today, Dynamic Document Capture technology offers additional automation intelligence for automated processing of semi-structured documents like sales orders and invoices, which contain consistent information in varying layouts and formats. Dynamic Document Capture technology improves recognition and accuracy, helping organisations eliminate traditional issues with managing different types of inbound business documents.
The ultimate purpose of this white paper is to help CEOs and CIOs understand the business value of operational efficiency gains, cost savings and error reduction resulting from document processes automation. In reading this paper, it is crucial to keep in mind what you want to do with the information in documents that come into your company and launch business processes every day.
Document Capture Basics
What is it?
Relative to the different types of documents that enter an organisation in various formats and via different channels, document capture is the ability to automatically import different types of documents in different formats into a document management system.
This inbound document automation has its beginnings with inbound fax routing functionality. With the emergence of OCR technology, organisations have gained the ability use the content of inbound faxes by converting images to a “readable” format. Rules-based automation technology enabled routing and archiving of inbound documents arriving by fax. But recognizing and using information contained in the inbound faxes for processing documents such as sales orders was prohibitive, as it was necessary to define a business rule for each type of sales order.
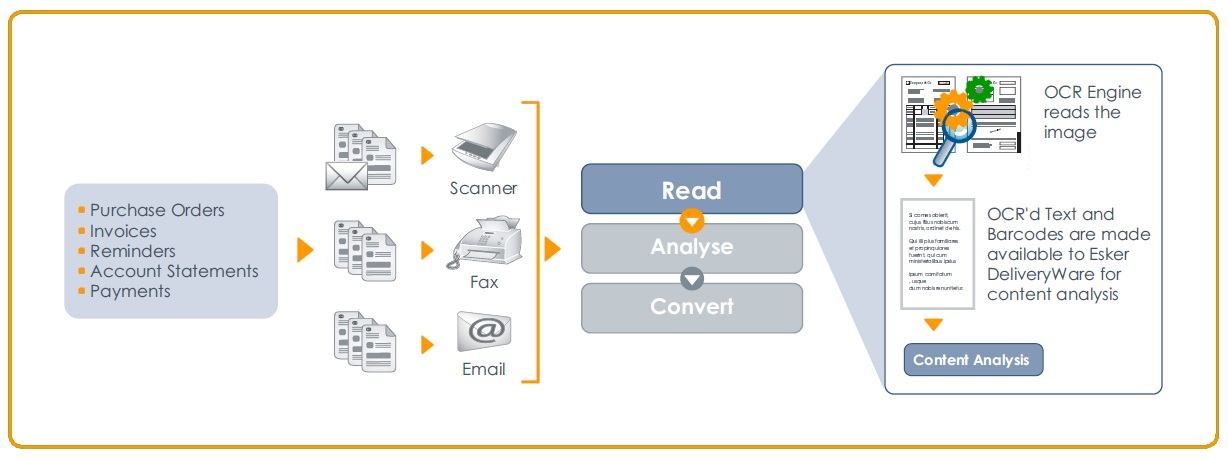
Document sources
Business cycles that have a direct impact on a company’s performance involve processes that begin and end with a document. For example, the order-to-cash cycle starts with receiving a sales order and finishes with sending an invoice. Sales order documents reach a company via fax, email, mail (paper documents) or even by phone.
In the case of phone order processing, customer service staff enter orders directly into the customer order system, often after filling out a form. But if the document arrives by fax, email or mail, the customer service representative must manually enter the sales order information into the appropriate system. The process of managing such documents is inherently inefficient and labor-intensive, and carries considerable risk of errors and/or lost documents.
And the issue of documents in relation to business process efficiency improvement is here to stay — because the volume of documents received every day by companies is constantly increasing.
The types of documents a business typically receives fall into three general categories:
- Structured documents
- Semi-structured documents
- Unstructured documents
To put things into perspective, today 20% of incoming documents are structured documents while 80% are semi-structured and unstructured.
Document Structure
Business documents are sometimes categorized as fixed content documents and dynamic content documents. Fixed content is the fi nal form of a documents such as contracts, invoices, statements, reports, technical documentation and even email. Dynamic content documents are created as objects that will undergo changes and modifications over time. Eventually, many dynamic objects become fixed, such as a contract that has been negotiated, modified and eventually finalized. This paper focuses on fixed content documents.
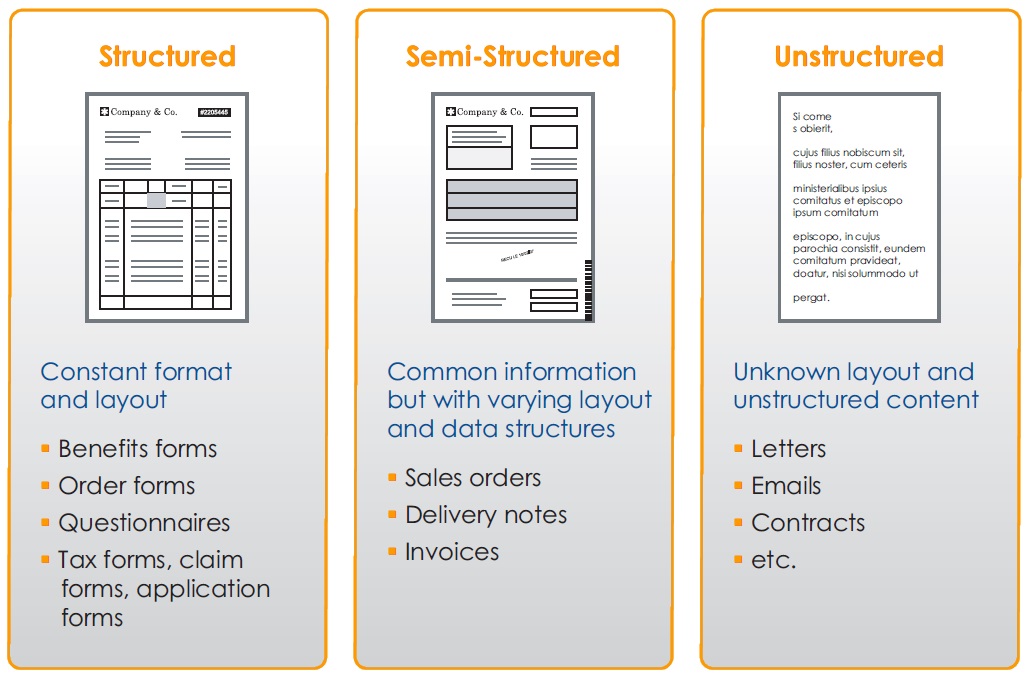
Structured Documents
Structured documents always have the same layout and an unchanging number of fields at a fixed position. For these types of documents, the goal is usually to extract data from a form and not necessarily keep the form. This data will then be migrated into a database for ERP, order entry, records, etc. The way to capture this information depends on the information. Such documents (health insurance claim forms, for example) are typically handled using OCR, ICR, OMR or barcode recognition. In this case, the best approach is to create a specific business rule for processing of each document type.
Semi-Structured Documents
Semi-structured documents have an unlimited number of variations, which makes the structured document approach inefficient. With semi-structured documents, data must be extracted from the document — no matter what its layout is — for entry into an ERP application or other business system. Information can be automatically read and extracted from semi-structured documents such as sales orders, purchase orders and invoices, providing the ability to define a generic rule for each type of semi-structured document. This is possible because these documents contain always the same type of data introduced by keywords.
Unstructured Documents
With unstructured documents, the document itself is what’s most important. You do not need to capture specific information from the page; you only need an image of the document so you can route and/or index it. Routing and indexing of such documents can be automated.
Optical Character Recognition
OCR functionality
Optical Character Recognition (OCR) technology gives scanning and imaging systems the ability to turn images of machine-printed characters into machine readable characters. Simply put, to translate the images into a form that a computer can manipulate.
OCR automatically recognizes characters on image files such as faxes (TIFF format) and PDFs attached to email. For example, you receive sales orders by fax and you want to archive them. You can read data on the inbound faxes you obtained and archive them according to their date, the source they come from or their amount.
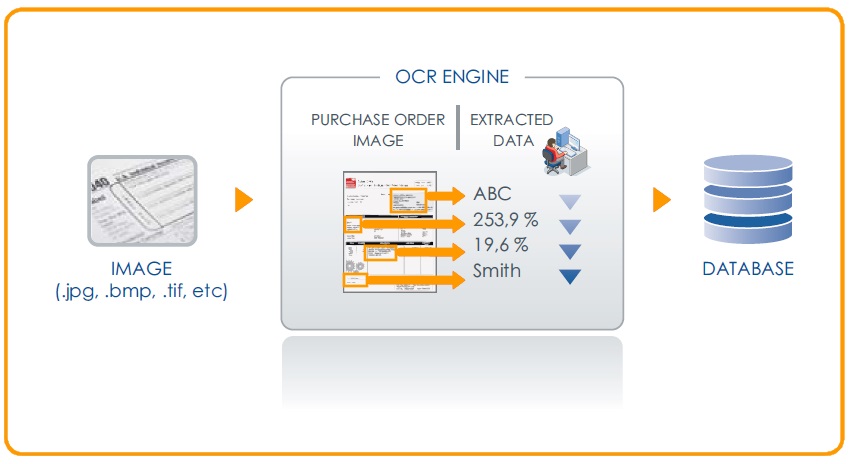
As OCR is not always 100% accurate, adding some type of validation step to the data workflow is necessary for quality assurance. A flexible solution enables users to check the recognition results from a web interface and allow the automatic process to continue.
OCR technology offers the capability to read information in document image files from scanners as well as fax and email. The OCR engine should support several languages, color as well as grayscale and black & white image input, multiple image file formats and image enhancement technologies like deskewing, auto-orientation and intelligent page-layout decomposition. These features help to optimize recognition accuracy.
A primary use of OCR technology is to convert data into reusable format so that it can be integrated with other systems and processes. Another application of reading data via OCR is to recognize the content of inbound faxes and thereby allow routing of these faxes according to both standard telecommunications data (such as the caller fax number) and fax content such as a name on the cover page. Inbound faxes can then be archived or routed to different user types (email, printing, web publishing, etc). OCR is also optimal for extracting text from PDF documents (typically received as email attachments).
Beyond imaging and the limitations of OCR
Scanning documents can help to address data and document issues such as security, efficiency in data search and retrieval, document distribution and auditing. And in efforts to reduce paper handling costs, imaging has become a basic method to archive documents and data in image files. To reach the next level of process efficiency, it is necessary to recognize the content of such files. Making data contained in documents available to other applications offers added value by replacing manual keystroke entry of entry into ERP systems. Moreover, automation of structured and semi-structured faxed or scanned documents relies heavily on successful image recognition. Skews and shifts, stretching and shrinking on faxed or scanned documents can lead to less than accurate recognition of defined areas.
Additional flexibility is offered by recognition that is not based on defined areas, but rather on the content of documents — keywords (located anywhere in the document) and fields to extract data and make intelligent assessments of document type and data required for processing. Compared with OCR alone, this type of technology offers vastly improved extraction accuracy with the ability to continuously “learn” how to handle different types of document formats automatically. The more a dynamic system like this is used, the more efficient it and your organisation becomes.
Recognition rates with OCR alone can be as low as 60%, depending on the quality of the electronic document and any additional technology needed to facilitate capture. OCR only reads an image and translates it into text. Beyond this, OCR does not “understand” content and how words relate to each other. In contrast, Dynamic Document Capture technology provides the ability to look for positions relative to key information. This additional business intelligence and logic ensures that accuracy of the capture does not only rely on OCR. This type of system is also able to run checks such as calculations and database lookups.
Dynamic Document Capture
Automation helps organisations raise operational efficiency by reducing document processing time and costs, whether the document is coming in from outside the company, flowing through the company or going out of the company to a customer or supplier. Dynamic Document Capture capabilities facilitate automatic processing of electronic or scanned semi-structured documents such as invoices, sales orders, shipping papers, etc. — recognizing and capturing information that resides in these business documents, and making them readily available in enterprise applications independent of format.
With Dynamic Document Capture you can speed up business processes and:
- Free your business from paper-based workflow
- Increase data entry accuracy
- Simplify document search and retrieval
- Enhance security of business data and documents
Using business rules technology, Dynamic Document Capture allows intuitive rule customization via a server-based graphical interface. Dynamic Document Capture incorporates OCR and ICR technologies to read information contained in image files whether they have been scanned or have arrived by fax or email.
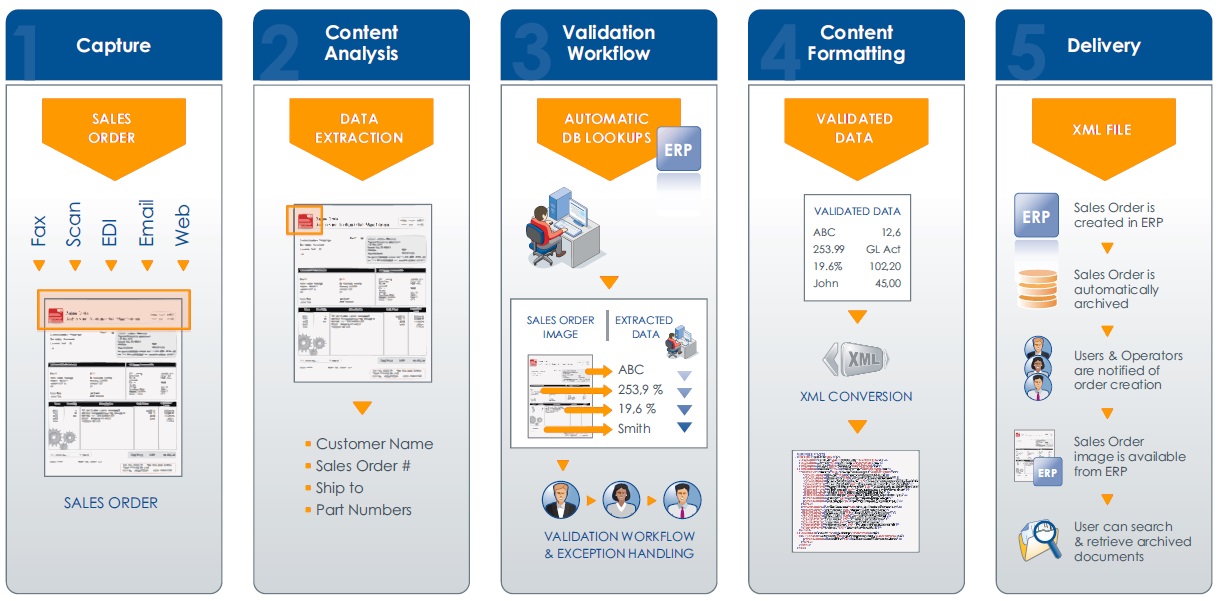
Additionally, Dynamic Document Capture uses logic, keywords, relative positions and business rules to allow relevant document data to be extracted. In a sales order scenario, the system automatically extracts the customer name and ship-to address, document date, number and total as well as line items such as quantity, description and amount. All information necessary to complete the sales order processing is captured directly from the document, regardless of its location within the document.
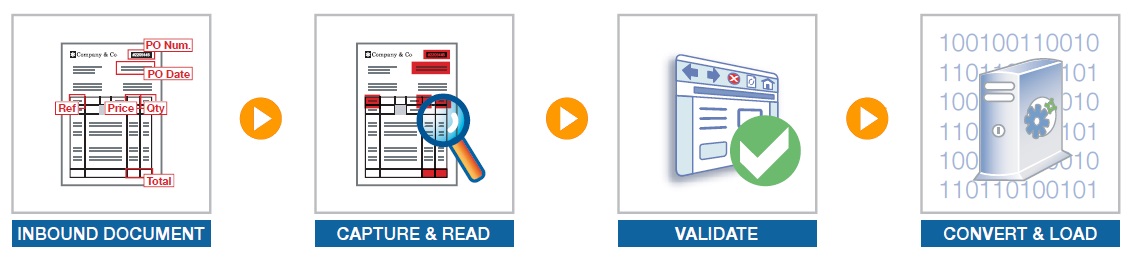
The ideal system comes with a set of predefined rules for processing for specific types of documents, such as sales orders. One rule extracts the information from inbound faxes or scanned documents. A validation form is used to validate extracted data. The output is an XML file which contains the extracted data and that is submitted to another rule for processing.
Dynamic Document Capture enables enterprises to avoid the cost-prohibitive task of defining a rule for each document variation, specifying the data you want to capture (data required for accounting purposes such as sales order number, invoice date, payment date, supplier references, totals, etc.) instead of specifying an area where it is located. Most of the time, data is introduced by keywords. For example, the total amount is introduced by the keyword Total. A generic rule captures data that is introduced by those keywords.
Because it is impossible to take into account the wide variety of different designs, Dynamic Document Capture lets you teach the generic rule to solve possible conflicts (for example, documents on which a keyword appears twice) or to improve system performance. Through a web interface, administrators and end users have the ability to improve recognition conditions or optimize document identification during document validation. With its intelligent business rules logic, Dynamic Document Capture is “free form” extraction that makes sense for semi- structured documents.
How Dynamic Document Capture Works
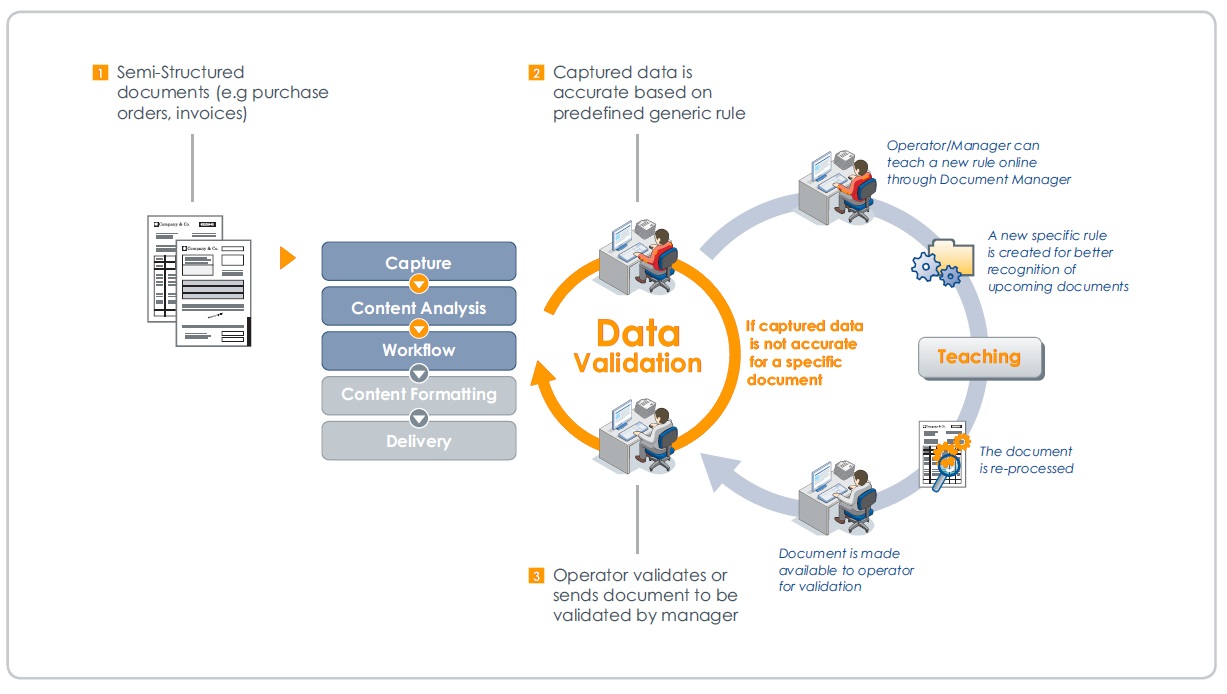
Capture
Data contained in incoming business documents such as sales orders and invoices can be captured from faxes, scanned images, EDI, email attachments, web or other formats and media.
Read
Relevant document header, footer and line item information can be extracted regardless of document layout or number of pages. The validity of the extracted data is automatically cross-checked according to predefined scenarios, and against company databases when necessary. This additional business intelligence and logic ensures that accuracy of the capture does not only rely on OCR technology to manage documents such as scanned or faxed images.
Verify/approve
After the data is automatically captured, users are presented with a simple interface to double-check correct recognition of the data. Users can compare data extraction against the displayed image of the original document. Additionally, the interface displays warning and errors messages next to the captured fields when necessary to draw the user’s attention to identified or potential issues. For example, when a new customer has been detected or if a possible duplicate document has been identified. When this stage is complete, the user will have the choice to save for later processing, approve, reject or even forward the validation to another user.
Load data and document
Once the information is correct, it can be used to “fill in” other applications — together with the original document image — and to create new business documents if necessary.
The iKAN Virtual Document Center Solution
Document process automation
iKAN offers a single platform for automation of document-intensive business processes without technological restrictions. As a comprehensive tool designed to help organisations reduce the use of paper, iKAN VDC makes document processing faster and easier to manage — regardless of the information source or method of delivery. iKAN VDC eliminates manual touch points and brings visibility to document processes while causing no disruption of current business operations.
iKAN VDC brings Dynamic Document Capture together with automation technology to help companies address the challenges of manual data entry, manual document routing and filing, lack of coordination and lack of transparency associated with conventional methods of processing customer orders, vendor invoices, claims, expense reports and other incoming documents.
Key Benefits of Dynamic Document Capture
- Remove slow and costly paper handling from business processes
- Eliminate error-prone manual data entry
- Improve process efficiency based on Key Performance Indicators
- Save time and money spent on manual document archiving and retrieval
- Support and enhance regulatory compliance efforts cost-effectively
0 Comments